背景・技術概要
ゲームやアニメーション、映画などのコンテンツ作品では、効果音を入れることが必要ですが、プロでもその制作には手間がかかることが多いです。ましてや、経験が少ない人にとっては所望の効果音を制作したりサウンドライブラリから選び出すことは大変骨の折れることであり、思い通りの音が作成・入手できるとは限りません。ですが、イメージする音をニュアンス含めて口真似で表現することは比較的容易であり、誰でもある程度はものまねとして表現できます(例:金属のぶつかる音、サイレンの音、爆発音など)。そこで、この研究では、口真似音声(特にボイスパーカッション的に似せた音)から、生成系の深層学習技術を用いて効果音を合成する技術について取り組んでいます。非音声、非音楽な音響合成技術です。そのような音には、現実世界で起こる「環境音」(Environmental Sound)や、非現実な音やユーザインタフェース音も含め様々な演出に使われる「効果音」(Sound Effect)があり、本研究は特に後者(効果音)に注目しています。手法の特徴としては、文字(記号)では表現しきれない発音を含めた音の種類(音韻情報)を扱うことに主眼が置かれているほか、音の高さや抑揚、タイミングなどの情報(韻律情報)も含めて合成します。現時点では、数ある効果音の種類の中でも、特に「爆発音」の合成に焦点を当てて取り組んでいます。(爆発音は、仮に文字で書いても、「ドゥーン」「ドァーン」「ボガーン」「ビシャーン」「バーーン」など多種多様な表現があり、これらの間の発音となる音韻もいろいろありえます)
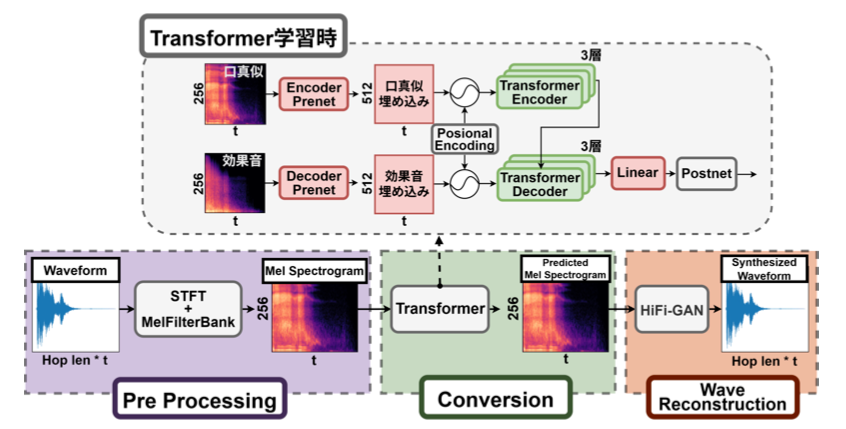
現時点の具体的な手法には、GPT等のLLMで使われているTransformerを用いた深層学習を行っています。学習するデータセットに、映画やアニメなどで実際に利用されている効果音と、それら効果音毎に人が発話した口真似音声とで、対のデータとして多数用意し、Transformerで学習します(「効果音」のソース音源と「人の口真似音声」の時系列変化の関係性を学習)。ここでは、音の波形を学習するのではなく、周波数成分の変化も含めた学習するため、各波形をメルスペクトログラム(画像的な2次元配列)に変換し、それらの対を学習します。生成時のTransformerの出力はメルスペクトログラムで、それを音響波形に変換するには、ニューラルボコーダ(Neural Vocoder)を通じて波形へと変換します。ニューラルボコーダにはHiFi-GANを使用しています(当初はiSTFTNetでした)。
合成音の例
- 口真似音声とそれに対する合成音の例(日本音響学会2024秋発表時)
- 入力メルスペクトログラムの次元数違いによる合成音の違いの例(ACM UIST2024発表時)
- 複数人の入力音声に対する合成音の例(音学シンポジウム2025発表時)
PronounSEの活用・使い方
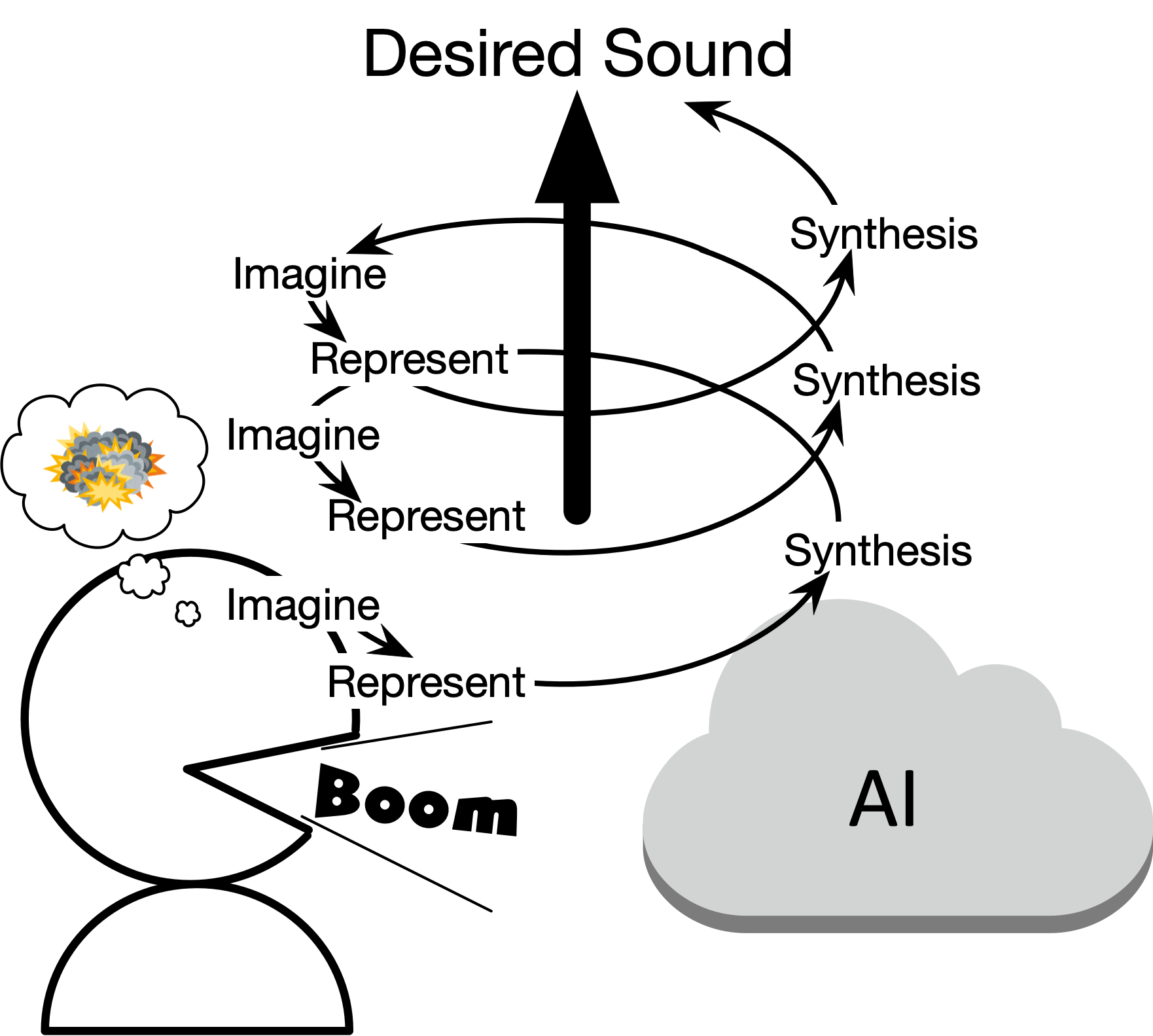
このような口真似発音したものが効果音として合成される処理(俗に言うAI)が実現できると、効果音作成の方法として、次のように繰り返して発音してイメージした音に近づけていくことができるようになります。
- 人は欲しい音をイメージする
- 口真似で似せた音として発音する
- AIがその発音を元に効果音を合成する
- 人は合成音を聞き、欲しい音か確認する
(1から4を繰り返す)
これは、人とAIが共に作業してゆく共創の一つの形だと考えています。
研究成果
- 対外発表
-
- 滝沢力, 平井 重行, 金崎朝子, 須田仁志: 言語非依存な口真似による効果音合成手法PronounSEの評価, 情報処理学会研究報告 2025-MUS-143, 51, pp.1-7 (2025) 【優秀発表賞受賞】
- Riki Takizawa and Shigeyuki Hirai, PronounSE: SFX Synthesizer from Language-Independent Vocal Mimic Representation, Adjunct Proceedings of ACM UIST2024, Article No.21 (2024)
- 滝沢力, 平井重行: 言語非依存な口真似データセット構築と口真似のみからのTransformerによる効果音合成, 日本音響学会第152回研究発表会,3-6-2 (2024)【学生優秀発表賞受賞】
- 滝沢力, 平井重行: 複数話者の擬音的発話音声データセットによる効果音合成の試み, 情報処理学会研究報告 2024-MUS-140(5), pp.1-7 (2024)
- 滝沢力, 平井重行: 擬音的発話音声からの効果音合成とその深層学習手法の改良, 情報処理学会第86回全国大会講演論文集, 1R-03(2024)
- 滝沢力, 平井重行: 擬音的発話のニュアンスを反映するインタラクティブ効果音合成, 情報処理学会インタラクション2024, インタラクティブ発表 1B-34(2024)
- 平井重行, 滝沢力: 生成系AIを活用した効果音制作手法の研究, CEDEC2023 ショートセッション (2023)
- 平井重行, 滝沢力: Transformerを用いた効果音合成技術 -爆発音を対象に-, CEDEC2023 インタラクティブセッション I-9 (2023)
- 滝沢力, 平井重行: オノマトペ音声を用いた効果音合成技術におけるニューラルボコーダの検討, 情報処理学会研究報告 2023-MUS-137(40), pp.1-6 (2023)
→注)予稿に書いてあるiSTFTNetの処理結果には、我々のプログラム上のミスがあり、正しくない記載内容が含まれています。誠に申し訳ありません。 - Riki Takizawa and Shigeyuki Hirai, Synthesis of Explosion Sounds from Utterance Voice of Onomatopoeia using Transformer, Companion Proceedings of ACM IUI2023, pp.87-90 (2023)
- 滝沢力, 平井重行: 音韻と韻律を含めたオノマトペ音声からのTransformerによる爆発音合成, WISS2022論文集, デモ発表 2-B06 (2022)
【チームラボ賞受賞】 - 滝沢力, 平井重行: Transformerによるオノマトペ音声から爆発音への変換の試み, 日本音響学会 関西支部 第25回若手研究者交流研究発表会 (2022)
- 滝沢力, 平井重行: Transformerを用いたオノマトペ音声からの爆発音合成の試み, 情報処理学会研究報告 2022-MUS-134, No.55 (2022)
- 出版・作品展示・メディア取材・出演など
-
- フジテレビ「週刊フジテレビ批評」でのInter BEE展示紹介(2025/11/29放送)
- ラジオ日本「Happy Voice from YOKOHAMA」でのInter BEE展示紹介(2025/11/21放送)
- YouTubeチャンネル DCEXPO TVでのInter BEEブース紹介(2025/11/19公開)
- Inter BEE 2025のINTERBEE IGNITION × DCEXPOにてブース展示(2025/11/19-11/21)
- 図書「進化するヒトと機械の音声コミュニケーション Vol.2 ~AIの活用と感情に寄り添う音声認識・合成の新展開~」, エヌ・ティー・エス(2025/4/10発刊)(分担執筆:第1編・第3章第2節担当)
- 【CEDEC2023】画像生成AIでサウンドも生成できちゃう? メルスペクトログラム画像を利用した効果音生成手法, GameBusiness.jp (2023/8/29掲載)
- 「ポケモン」環境音の作り方から疑似もぐもぐまで。ゲームサウンドの新世界, AV Watch (2023/8/28掲載)